


Artificial Intelligence
1956–1980s
The Beginning
The person credited with first using the term artificial intelligence was a computer scientist named John McCarthy, who coined the phrase to describe the purpose of a study group he convened at Dartmouth College in the summer of 1956. McCarthy suggested that "every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it," and tasked the assembled experts to find out "how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves."
That inaugural conference fixed both the parameters and ambitions of what was to follow. As AI has evolved, it has come to mean not a single technology, but a smorgasbord of disparate techniques united by an ambition to recreate something of what it is to be human in machine form. For some but not all in the field, the end point is ",” or AGI: a machine that can do anything a person can.
Since those early days, there have been two approaches that have defined the quest to achieve artificial intelligence. McCarthy was a proponent of what has come to be known as , also known as Good Old Fashioned AI or GOFAI. This approach uses "if/then" logic as a foundation with which to explicitly program computers, together with algorithms for navigating these inferences and deciding which to apply when. (If Manhattan is in New York City and I am in Manhattan, then I must be in New York City.) The other approach, more familiar to anyone whose awareness of AI started within the last decade, is , which uses statistics to infer patterns from large amounts of data.
Over the years, each approach has gone in and out of fashion depending on its perceived potential at the time, though in the early days of artificial intelligence — the late 1950s and early 1960s — symbolic and statistical approaches were both seen as being full of promise. Thanks to symbolic AI, computers became capable of meeting cognitive challenges that could be broken down into steps of logical necessity, like playing checkers (adequately, not at an expert level) or answering simple queries about sports teams. Just as notably, machine-learning scientists back then were developing the basic principles that have come to underpin much of AI’s progress over the last decade.
By the late 1960s, interest in both approaches flagged when attempts at machine translation fell flat.
1980s
Boom, Then a Bust
Thanks in part to a steady growth in computational power and the accompanying development of new programs to harness it, symbolic AI got a second wind in the early 1980s, showing promise in diagnosing certain diseases, predicting tornadoes and troubleshooting mechanical problems in things like steam turbines and brake systems in cars. With so much seemingly unlockable potential, AI grew quickly from a cottage industry to one projected to produce billions of dollars of annual revenue. Enthusiasm led to grand pronouncements. “Experts project that A.I. programs will be designed that can teach children mathematical skills and drive trucks or automobiles,” read a 1985 New York Times story. An “AI alley” sprung up in Cambridge, Massachusetts, comprised largely of start-ups founded by MIT faculty and graduates.
But the boom didn’t last. The first new AI system to be used in business, called XCON, evolved into a joke: Sure, the technology had replaced 75 people at a single company, but it now required 150 people to maintain it. Many of the start-ups in AI alley declared bankruptcy; a billion-dollar Japanese government AI project was written off as a costly boondoggle. “Bringing the visionary technologies of artificial intelligence to the market has proved far more difficult than had been anticipated,” wrote John Markoff in a New York Times story published just three years after the paper had announced AI’s heyday.
Though few of the AI technologies of the 1980s took hold, the sting over their failures did. The loss of faith and financing for AI came to be known as , a cautionary tale about what can happen when hopes get too high that still hangs over the industry.
1980s–2000s
Machine Learning’s Neural Networks Take Root
Machine Learning, the second approach to AI –– and the one that has shown so much progress over the last decade –– includes a variety of approaches of its own, the most widely used of which are . Very loosely based on the structure of the human brain, neural networks use layers of computational nodes (the “neurons”) to sort, find patterns in and analyze data. Early versions, developed in the 1950s and ’60s — today referred to as shallow neural networks — had three layers: one outer layer for input, another for output and a middle layer between them. But the most commonly used neural networks today are those with multiple layers, which define what we’ve come to know as . For a variety of reasons, such networks were neglected until the mid-1980s. That’s when a small group of researchers that included Geoffrey Hinton and Yann LeCun — two people whose early work would lead them to become known as among the originators of deep learning — started down a path that ultimately led them to discover not only how such networks could be made to work, but how they could be put to dramatically productive use.
Deep learning is composed of its own sub-categories –– approaches that can be used to solve a variety of problems in a variety of ways. The principal techniques are supervised, unsupervised and reinforcement learning.
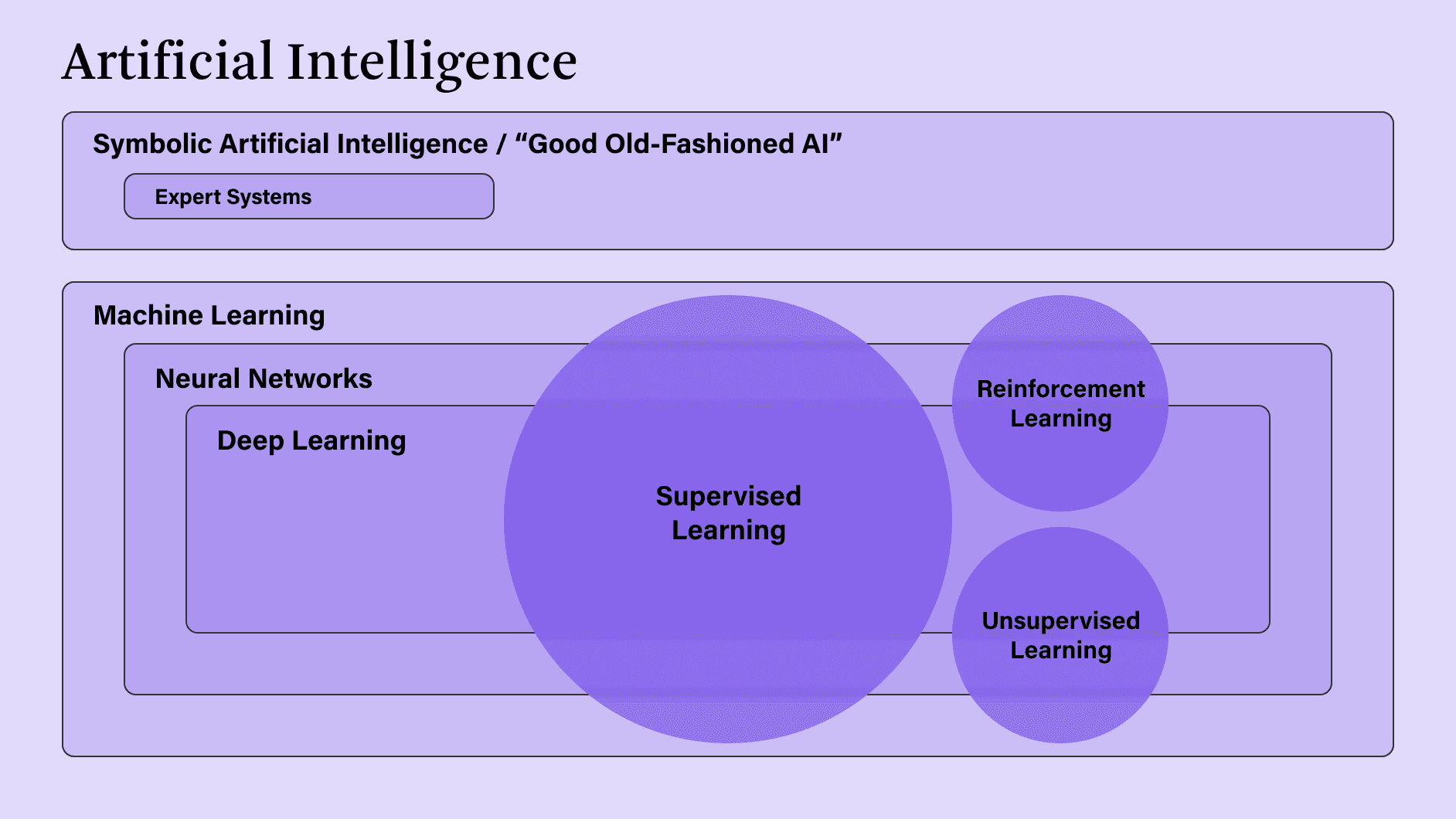
Supervised learning has been by far the most common approach in recent years, encompassing an enormous number of tasks including the standard techniques for speech and image recognition. The three most important hallmarks of a supervised learning problem are: 1) It has a specific and defined goal, say, identifying cats; 2) There is an enormous amount of available data (images of cats) that can be labeled in order to train the system; 3) It is possible to create a rapid feedback loop, based on the labeling, that indicates whether a cat has been accurately identified or not. If such criteria are met, a deep learning system can be trained to identify cats.
Unsupervised learning is similar to supervised learning except that the process starts without a stated goal. It is used to identify anomalies in large data sets in situations where the anomaly has not been described beforehand. Fraud detection is a classic example: Machine learning can sort through masses of data, find consistent patterns, and then identify clusters of data that deviate from such patterns. Once such clusters are found and examined, they can then be labeled as fraudulent and used to train supervised learning systems.
Reinforcement learning is what is used when computers learn to play games like chess, or Go, or to solve a Rubik’s Cube. There isn't necessarily an established link between defined inputs and desired outputs (like a labeled set of images), but rather a process that ends with either victory or defeat. A process that leads to victory will "reinforce" the series of steps that led to such an outcome; a process that leads to defeat will, conversely, be discouraged. The most eye-catching applications of reinforcement learning have been in games, but it can also be useful for things like recommendation engines and in training models to, say, execute trading strategies.
(A note on terminology: While non-scientists tend to refer to the different kinds of machine learning as approaches to problem solving as we do here, computer scientists generally see different kinds of machine learning as categories of problems to be solved, such as, “Teaching a computer to play chess is a reinforcement learning problem.”)
The use of neural networks in each approach can lead to results that are widely scalable and stunningly accurate. (Such systems can identify everyday objects, if presented clearly, as accurately as humans and can identify barely discernible tumors in medical imaging.) But none of the approaches currently allow humans to easily understand how exactly results are achieved –– important information when delivering a tumor diagnosis or news of a rejected loan application. Current models also require an enormous amount of data and processing power to train. A 2019 paper found that training a single large AI model — one that might, say, run the speech recognition engine for a smart speaker like Amazon Echo — leaves a carbon footprint that is almost five times the size of that of the average American car, including its manufacturing. That said, while training and updating these models consumes enormous energy, running them does not, and some newer models are considerably more energy efficient.
2012–2018
The Deep Learning Explosion
The most common explanation for the machine-learning revolution of the last decade is that the exponential increase in computational power and memory described by Moore’s law, together with massive amounts of user-generated data, allowed us to make good on theoretical insights that had been around for at least four decades. But this, while true, is only part of the story. It’s not only that the technology caught up to some previously intractable problems, it is also that human researchers have been incredibly creative in their ability to recast old problems to suit new tools. Certain activities that had long been seen as tasks requiring human-level understanding — fraud detection, radiology and mail sorting — were reimagined as pattern-matching problems that could be solved through deep learning. The result was so powerful for some tasks that entirely new industries grew up around them. Today’s on-demand access to shopping, mapping, speech translation and cars for hire, as well as personally curated newsfeeds and sophisticated email filtering programs are all rooted in the pattern-matching abilities of machine learning. Such services have in turn helped to propel data-driven businesses like Amazon, Google and Facebook to become among the most profitable corporations in history.
The progress was so astonishing in certain industries that there was a rush to reduce as much human activity as possible to patterns that could be parsed by machines. Cars, the thinking went, would be able to drive themselves once enough patterns were derived from massive amounts of data about how humans drive. Virtual personal assistants would soon be part of everyday life because patterns could be found in millions of internet search requests.
In the midst of surging expectations, some experts expressed skepticism about the abilities of deep learning to continue to deliver all that was being promised. Michael Jordan, an eminent computer scientist, summarized some of the widely held concerns in a 2014 interview, pointing out that the fact that machine learning became very good at image recognition did not mean that it was capable of understanding how such objects would operate or interact with other objects in real-world situations — a significant limitation to some of the promises being made about the technology. “There are many, many hard problems that are far from solved,” he said, adding that “there’s a good chance that you will occasionally solve some real interesting problems. But you will occasionally have some disastrously bad decisions.” The failure to honestly reckon with the technology’s limitations, he warned, could result in a loss of faith and subsequently a loss of funding for future AI projects, possibly resulting in another AI Winter.
Still, the commercial momentum was formidable — companies like Waymo, Uber and Tesla projected that fully autonomous cars would be common on public roads by 2020 — and other scientists in the field expressed much greater optimism than Jordan. In 2015, Hinton, LeCun and Yoshua Bengio, a professor at the University of Montreal (and a former postdoc of Jordan’s), wrote a widely cited review in the journal Nature, predicting that "deep learning will have many more successes in the near future because it requires very little engineering by hand, so it can easily take advantage of increases in the amount of available computation and data. New learning algorithms and architectures that are currently being developed for deep neural networks will only accelerate this progress.”
2018–2020
AI Reveals its Limitations
Starting in 2018, reality began to catch up to the hype around AI, as deadlines came and went without the sort of progress that boosters had promised. Autonomous car companies had experienced a series of public setbacks involving crashes and several deaths, and earlier bullish projections were dialed back. In July 2018, Waymo’s C.E.O., John Krafcik, said that the “time period will be longer than you think” before autonomous cars would be common. An ambitious AI-powered virtual assistant called M that Facebook had announced in 2015 with great fanfare was quietly canceled in 2018. (It required the work of too many expensive humans to scale.) And Hinton himself has illuminated potential risks in relying on neural networks as substitutes for the human brain, pointing out that so-called adversarial examples — inputs to deep learning systems undetectable to humans that can be used, for instance, to trick systems into misidentifying images — reflect the extent to which neural networks operate in ways that are fundamentally different from human perception.
Even comparatively mundane AI projects were being questioned — victims of the profound gap between theoretical promise and practical implementation. Merely assembling the staggering amount of data necessary to implement deep learning, for example, proved to be a poorly understood barrier to entry. As Arvind Krishna, the C.E.O. of IBM, told the Wall Street Journal in May 2019, the firm’s clients were halting or canceling AI projects because of the data requirements: “you run out of patience along the way, because you spend your first year just collecting and cleansing the data. And you say: 'Hey, wait a moment, where’s the AI? I’m not getting the benefit.' And you kind of bail on it.”
What happened? A simple answer is that amid the undeniable transformation that AI has delivered in many areas, certain applications failed to live up to overblown expectations within impossible time frames. Many AI projects were committed to without a full understanding of the technology’s requirements and limitations.
More specifically, there is a growing and broad consensus among experts in the field of AI that supervised learning is reaching its limits. Skeptics and boosters agree that continuing to collate the enormous sets of training data needed to guide ever-more sophisticated supervised learning programs is not practical or scalable.
One response to this has been to advocate for new methods of machine learning. LeCun, for example, argues that there are underexplored approaches to machine learning that can pick up where supervised deep learning is hitting a wall. Others are focusing on combining symbolic AI and machine learning with the belief that this will create a hybrid form of AI capable of a more human-like understanding. So far, it’s not clear how promising any of these methods are. While it’s possible that one or more of them will advance with leaps and bounds, they are comparatively untested; there’s no reason to think they will experience the same kind of rapid progress that supervised deep learning has.
At the same time — particularly with a technology like autonomous cars — there is always the option of adjusting infrastructure to suit the technology. If today’s autonomous cars aren’t ready to safely navigate unpredictable city environments, for example, there’s nothing to say that we can’t start building and redesigning cities to suit the cars we have instead of waiting for the cars we want.
There is no doubt that AI has the potential to be an enormous boon to humanity. Safe, self-driving cars could save countless lives; machine translation systems are already helping bridge cultural divides; voice recognition systems enable people with certain disabilities to communicate more easily. At the same time, there are countless unresolved questions about how current AI systems operate and how they’ll be deployed in the future, from the ease with which bias can be embedded into AI, to questions about whether — and how — data collected for AI systems can be protected. While AI can outperform humans in many ways, it can also massively scale human flaws and errors. Thomas Dietterich, a former president of the Association for the Advancement of Artificial Intelligence and co-founder of the Journal of Machine Learning Research, has warned that “as society contemplates deploying AI in self-driving cars, in surgical robots, in police activities, in managing critical infrastructure, and in weapon systems, it is creating situations in which errors committed by human users or errors in the software could have catastrophic consequences.”
One possible benefit to experiencing the radical transformation that AI has delivered to certain areas of our lives while simultaneously witnessing its failure to immediately transform others is that we now have time to assess and consider AI’s power during what might be a pause in the action. What do we want from it, and how can we curb its potential dangers?
The Future
Will AGI Become a Reality?
The possibility of achieving artificial general intelligence has always been embedded in the pursuit of more practical — and practicable — forms of AI. But the belief among those working in AI and AI-related fields that AGI is both a worthwhile and achievable goal is far from universal. It is not a subject that is rigorously polled, but there have been a few informal surveys that illustrate varying opinions on the subject. Two thirds of AI experts in one survey said that, despite recent progress, anything resembling human-like intelligence won't be attained for at least 25 years, and a quarter of them said it will never happen.
Nevertheless, the goal of artificial general intelligence exists as a kind of North Star, often framing discussions about future developments in AI. Proponents of AGI claim that it is only a matter of time until AI-powered machines can act with the nuance and complexity of human beings and therefore deliver breakthroughs in areas like fully autonomous cars. For others, the failure of supervised deep learning to meet certain expectations of the past five years has given new fuel to doubts like the ones expressed by Jordan — that not even the most sophisticated version of deep learning will be able to achieve or even approach the kind of human-level intelligence required to, say, reliably operate a car in New York City.
Brian Cantwell Smith, a computer-scientist-turned-philosopher and a colleague of Hinton’s at the University of Toronto, argues that the “epochal significance” of AI requires a new framework for what it means to be human and that the quality that will distinguish us from machines is judgment, “a form of thinking that is reliable, just and committed — to truth, to the world as it is.” He warns, however, that judgment can’t be taken for granted, that we must deliberately strengthen our commitment to “dispassion, ethics and the world” and not try to compete with machines on their terms.
The discussion forces into relief the concept of human intelligence itself, and how exactly it can be defined and parsed. Is it being able to discern right from wrong? Seeing that an object is about to fall and being able to catch it? Knowing that chess is a game that is played for fun? Knowing what "fun" is?
And will it be technologists, neuroscientists or philosophers who are best equipped to grapple with possible answers?